
Stable Diffusionを使っていくつか画像を作成していくと、このような欲求が湧くはずです。
「ああ、このモデルをアバターのように喋らせてみたい・・・。でも難しいことはできない・・・」
そんな時、D-ID社の「Creative Reality Studio」というサービスを使えば、その欲求はすぐに満たす事ができます。
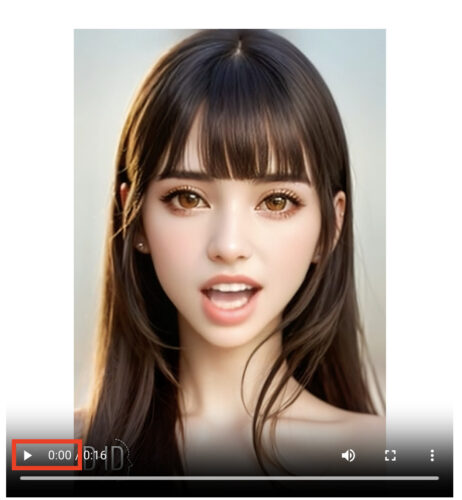
例えばこのように、画像を喋らせる事ができます。(↓再生してみてください)
まあ少し違和感はあると思いますが、自分の作ったモデルが、難しい操作なく、このようなクオリティで喋るのは単純に嬉しいです。
トライアルでいくつか無料で作成できるので、ぜひ作成した画像を喋らせてみましょう!
AIで作成した画像をアバターとして喋らせる方法
サイトへアクセスしアカウント作成
「Creative Reality Studio」はWeb上で使えるサービスです。
ますは公式サイトへアクセスします。
右上の「FREE TRIAL」を選択します。
一覧から「Create Video」を選択。
「Choose a presenter」の「+ADD」を選択します。
サインインを求められるので、アカウントを作成します。
アカウントを作成したら、いよいよ画像を喋らせていきましょう。
アバターの作成
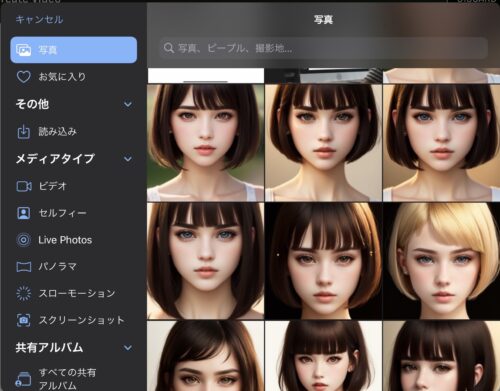
「Choose a presenter」の「+ADD」から画像を追加していきます。
保存してある画像を選んでいきましょう。
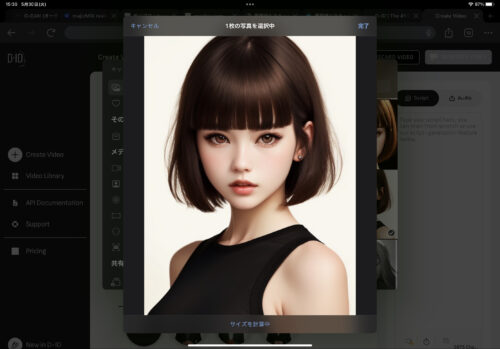
画像を加えたら、喋らせるテキストを入力します。
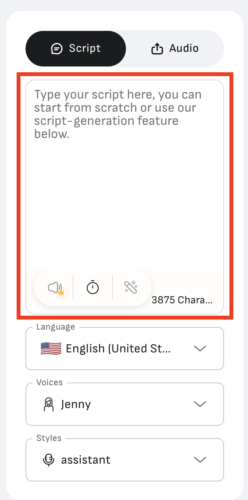
次に「Language」で言語を選択。
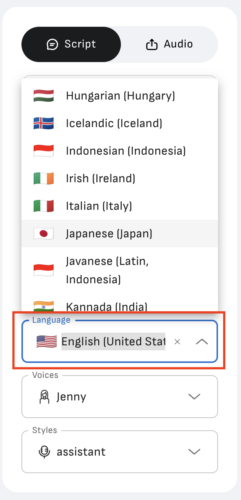
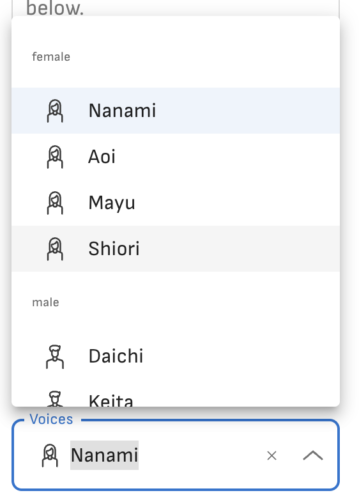
お次は「Voices」で声を選択。女性と男性があります。
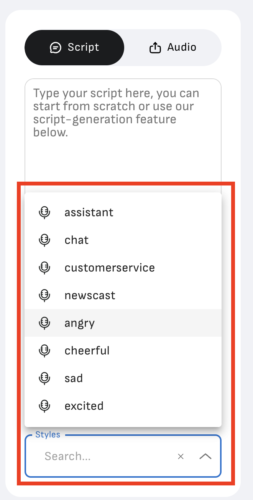
「Styles」は声の表現方法(おしゃべり、怒った感じ、元気いっぱいの感じ、などなど)を選択できます。※対応している声に限ります
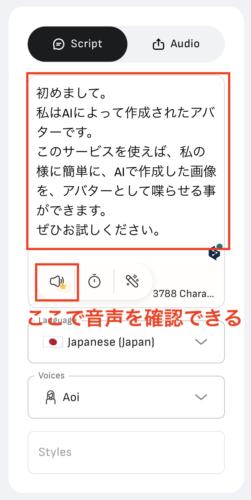
テキスト、言語、声などの設定が終わったら、「音声」アイコンを選択して試聴することができます。
ここで選択した声はどんな感じなのか、テキストに違和感がないか、などを確認しましょう。
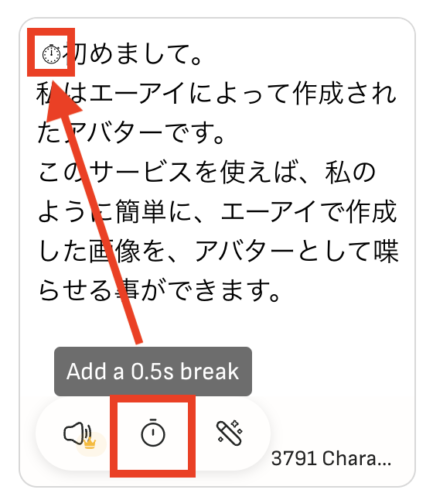
ちなみにこのまま動画を作成すると、開始時間の顔が口を開けた状態になってしまいます。
気になる方は、テキストの初めに「時計」アイコンで0.5秒の休止時間を作ると、開始時間でも口を開けないでいてくれます。

良い感じに調整が終わったら、画面右上の「GENERATE VIDEO」→「GENERATE」と選択していきます。
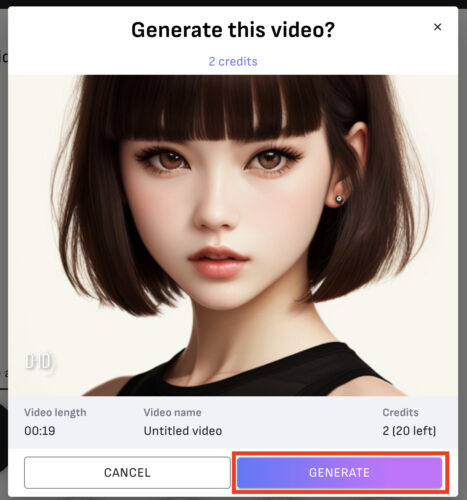
動画の作成が始まり、完了したらモデルのおしゃべりを確認する事ができるようになります。

ちなみに作成した動画は「Video Library」という場所に保存されます。
以上、お疲れ様でした!
いくつかアバターとして喋らせた結果
ここで作成したアバターを少し紹介します。(↓再生できます)
こちらは日本語のイントネーション等に若干違和感があるものの、許容範囲と言えるでしょう。
英語の方がよりナチュラルです。
失敗例
とはいえ、実はこのサービスは癖があり、うまくいかないことも多々あります。
ということで失敗例をいくつか。(失敗例は画面キャプキャでお送りします)


悪くないですが、左目が大きく違和感があります。
髪が目にかかっている画像だとこのような形になるようです。


いや、口まわりの癖!


おおい!どうしてこうなった・・・
とにかく全般的に口周りのクセが強いのが特徴で、日本人などアジア系のおとなしい顔には、大袈裟すぎて違和感があります。
こちらのモデルのように、ハーフのような顔であれば、違和感はだいぶ減ります。

この辺は試行錯誤と、動画を再生してみるまでわからないガチャ要素(運要素)があります。
まとめ
ということで、AIで作成した画像を喋らせる方法をお伝えしました。
アカウントを作成すれば、無料で簡単に試せます。
少し癖がありますが、自分が作成したモデルを喋らせるのなかなか楽しいので、ぜひトライしてみてください。
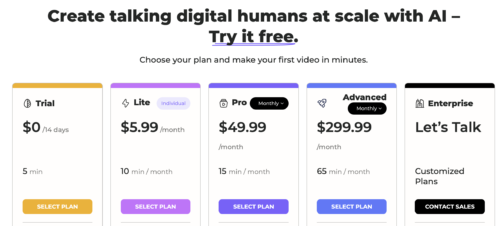
トライアルは14日間、トータル5分の動画が作れるので、きっと良い感じのものは作れると思います!
コメント